GPU Architecture
- CPU vs GPU characteristics:
- CPUs are latency optimized ,GPUS are throughput optimized.
- CPU ⇒ Sports Car → minimize the total time of trip for one person
- GPU ⇒ bus → optimize for the number of people moves per hour
- We achieve higher throughput
- Terminology:
- CPU = “host”
- GPU = “device”
- Kernel = GPU function executed in parallel across many threads. Fundamental unit of execution in CUDA.
| Component | CPU Time(ns) | GPU Time (ns) |
|---|---|---|
| FMA | 1 | 5.2 |
| Register Access | 0.3 | 5.2 |
| L1 Access | 1 | 25 |
| L2 Access | 2.5 | 260 |
| DRAM Access | 63 | 520 |
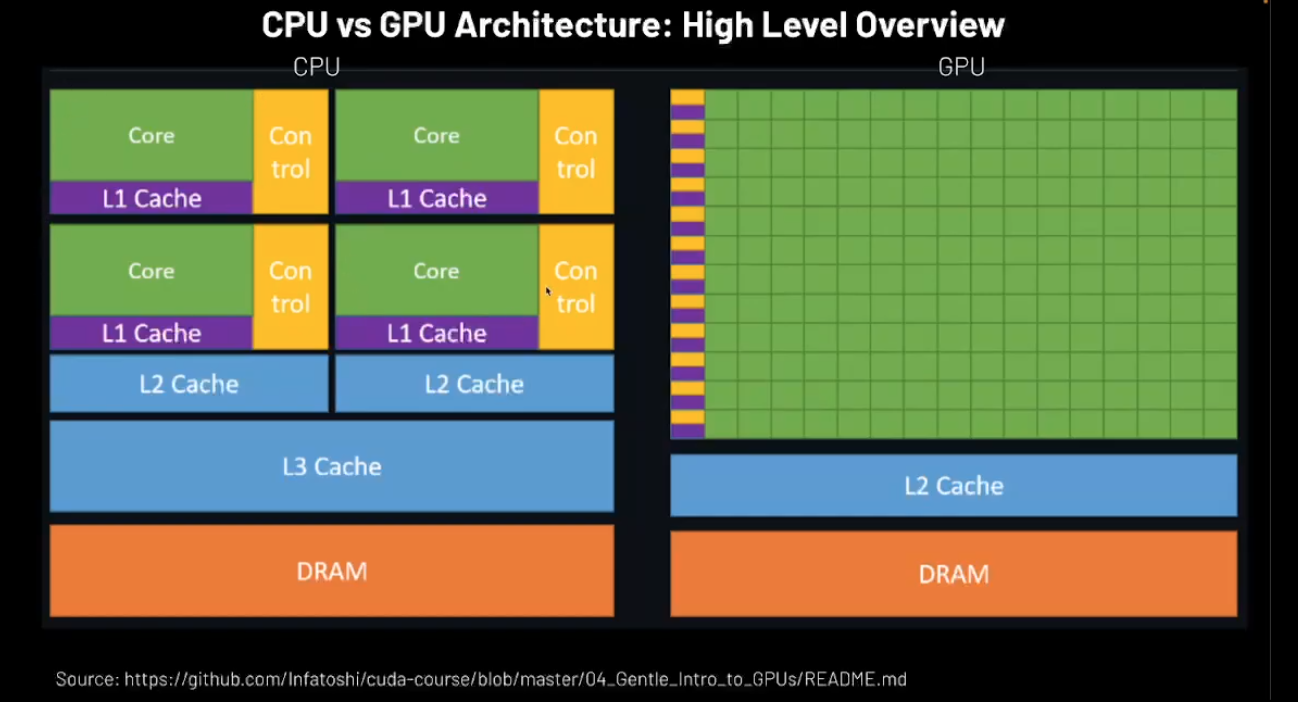
CPU vs GPU High Level architecture
-
CPU cores are high performance cores that are optimized for low latency serial executions
- Our true degree of parallelism is limited to the number of cores that are allowed.
- DRAM , L3 Cache → Common across the cores
- Slighly bigger L2 cache than L1 cache.
-
The GPUs have more higher number of cores → small and can lead to higher latency → but they are huge in number.
- These indv cores are not as powerful as CPU cores → but can achieve parallelism and higher throughput than CPU cores.
- Shared L2 cache and shared memory in DRAM.
-
Actually these exist in “streaming multiprocesser” → higher the number is better.
Streaming Multiprocesser

-
Composition:
- An SM consists of multiple arithmatic logic units (ALUs), special function units,and memory (eg: registers,shared memory)
-
Instruction Parallelism:
- An SM executes threads in groups called warps. A wrap is a group of typically 32 threads on NVIDIA GPUs.
- All threads in a wrap execute the same instructions in the same order → (SIMT - single instruction multi-threaded execution model).
- SIMT is a generalization of strict SIMD in which threads can diverge in execution paths (due to conditional branching)
- All 32 threads execute the same set of instructions, in the same order , but may operate on different data.
- The GPU is not working with individual threads but dealing with warps. → these are chunking through parllel group of computations through it. → hides memory complexity.
-
Control Logic:
- The SM contains scheduling hardware to manage the execution of multiple wraps and switches between them to hide memory latency.
-
We have specific tensor cores → specialized cores that are specialized hardware for doing matrix multiplication . → good for deep learning architectures.
-
Warp Definition:
- A warp is the smallest unit of execution within an SM. It consists of a set of threads (eg: 32 threads on NVIDIA GPUs) that execute the same instruction simultaneously but on different data (SIMD - Single Instruction, Multiple Data Model).
-
Warp Execution:
- The SM schedules warp for execution. At any given time, the SM might execute on warp, switch bw multiple warps, or stall if there are dependencies or resource constrainsts.
-
Concurrency:
- An SM can manage multiple warps concurrently, depending on the hardware’s capability(eg: the maximum number of active warps per SM). The total number of active threads is constrained by resources like registers, shared memory, and the architecture’s warp limit.
-
Divergence Handling:
- Within a warp, all threads must execute the same instruction. If threads within a warp diverge(Eg: due to an if-else branch), the SM handles each divergent path sequentially, potentially reducing efficiency.
Latency comparison of memory/cache access versus computational operations.
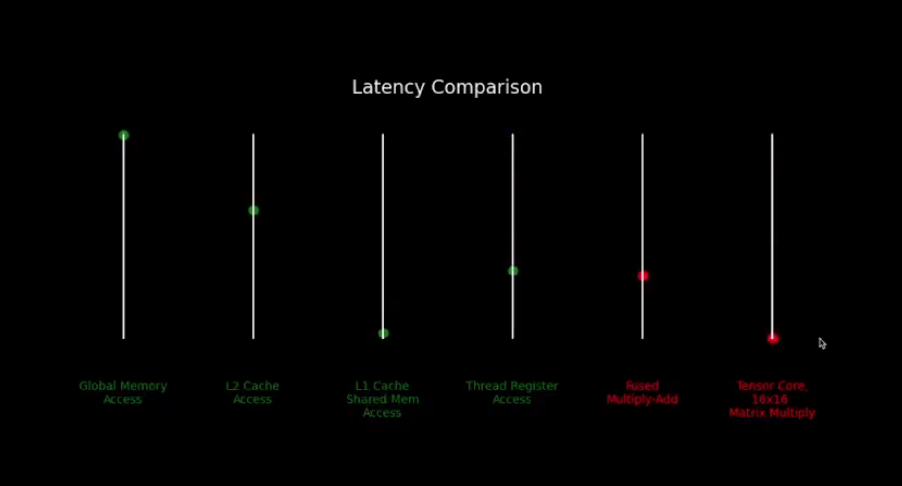
- thing that we will grapple with training workloads/ ML workloads generally is that :
- to scale well, try to overlap / hide our memory access latency - network computations.
- find someway not do useful compuatations and not be blocked in some way.
ML at Scale and How GPUS fit in:
-
System Diagram of GCP A3 VM with 2 H100s 80GB GPUs
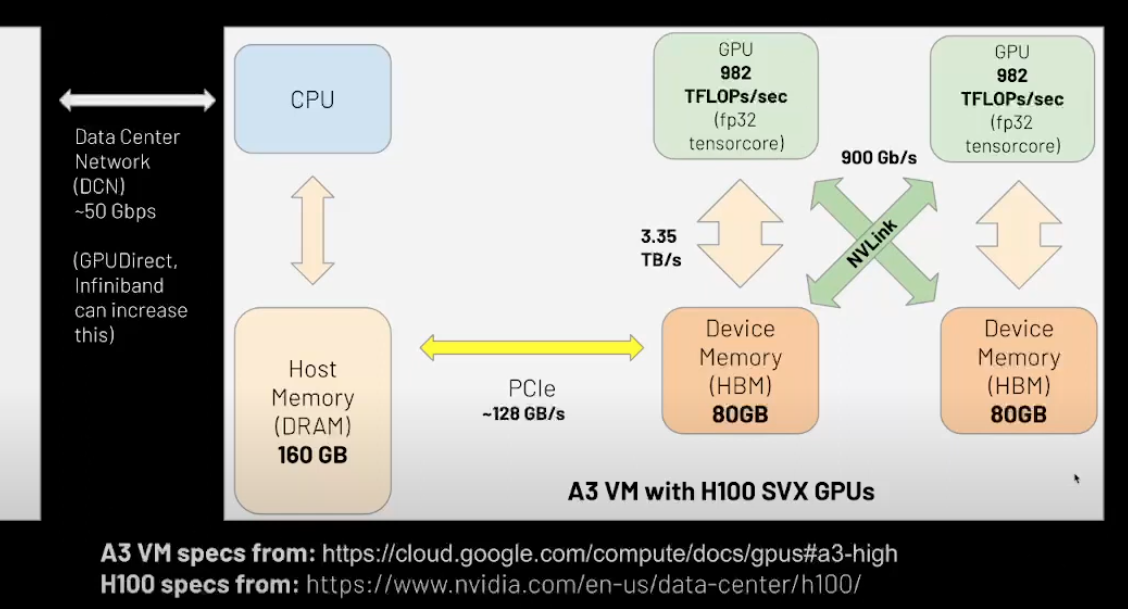
- PCIe → to move data to and from host memory and data memory.
- NVLink → how fast can interchip communication happen
- The slowest network is our DCN and is a resource constriant will designing our ML at Scale applications.
- Infiniband → specialized network link and network protocol that can give higher network bandwidth.
- GPUDirect → RDMA technology, allows to skip these steps of multiple copies ; allows the GPU and NIC to integerate directly.
- GPU →
- Compute Constraints → floating point 32 data type, 982 tflops/s, dwarfs many of the other numbers.with all these constraints , our network bandwidth and so on, we are gonna struggle to feed GPU data quickly enough , to use all that power unless we carefully arrange when and how we move data over the network → overlap it with computation → or maybe do compiler optimizations like kernel fusions.
- or do more floating point operations that come in it.
- From the official NVIDIA developer docs, the imbalance grows with lower precision data types.
-
One way is to think compute as a factory → we send instructions to our factory (overhead), send it materials (memory bandwidth), all to keep our factory running efficiently (compute).
-
So if our factory increases efficiency faster than the rate at which we can supply it materials, it becomes harder for our factory to achieve its peak efficiency.
-
Important metrics for comparing the performance of GPU performance:
- Arithmatic Intensity
- ratio of FLOPs/bytes moved back and forth across HBM
- Arithmatic intensity of the workload roughly equals to the arithmatic intensity of the hardware ? Compute bound → so we perfer this.
- MFU
- Model Flops Utilization; value bw 0 and 1 representing the ratio of the actual FLOPs/sec achieved vs peak FLOPs/sec achievable on this hardware.
- Also advertised in company blogs and stuff. avg is 45-55% not 100% for distributed training.
- Arithmatic Intensity
Key Takeaways:
- GPUs are optimized for throughput, not latency.
- FLOPs/sec >>> memory bandwidth, memory access latency, network bandwidth
- Peak FLOPs growing faster than HBM bandwidth.
- We prefer workloads to be compute bound, not memory bound bandwidth bound.
CUDA:
- CUDA(Compute Unified Device Architecture) is a parallel computing platform and programming model developed by NVIDIA that enables developers to use GPUs for general-purpose training.
- Provides an extension of C/C++ ,allowing code to be executed in parallel across thousands of GPU cores:
- *.cu files
- nvcc compiler
- Concretely, it provides a programming model with software abstractions for defining and executing kernels on NVIDIA GPUs.
CUDA Programming Abstractions:
Hierarchy:
- Kernel executes in a thread.
- Threads grouped into Thread blocks (aka blocks)
- Threadblocks defined by the dimensions of how many threads / dim they are. Dont need to use all dimensions that are available to use.
- Blocks grouped into a Grid
- Break up your whole grid into threadblocks
- Kernel executed as a Grid of blocks of Threads.
4 Technical Terms:
gridDim→ number of blocks in the gridblockIdx→ index of the block in the gridblockDim→ number of threads in a blockthreadIdx→ index of the thread in the block.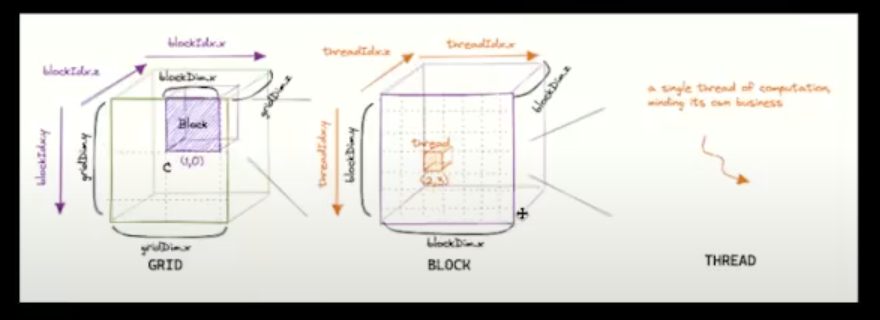
- CUDA Kernel is a function that runs in the GPU across many different threads.
- when we launch the kernel we have to pass in many different things, i.e the 4 technical things we listed up there.
Simple CUDA Program → Naive MATMUL on CPU vs GPU (CUDA Kernel)
- CPU allocates data structures in CPU memory.
- CPU Copies data to GPU HBM.
- CPU launches kernel on GPU (processing is done here)
- GPU loads data from HBM to SRAM (on-chip memory)
- CUDA runtime and SM warp schedulers work together to divide thread blocks into warps and execute them.
- Result moves from SRAM to HBM.
- CPU copies results from GPU HBM back to CPU memory to do something useful with it.
% % writefile gpu1.cu
#include <stdio.h>
#include <stdlib.h>
int main() {
//block size
int BLOCK_SIZE = 16;
//define the input size
int M = 512, K = 256, N = 512;
// host matrices
float * h_A, * h_B, * h_C;
//device matrices
float * d_A, * d_B, * d_C;
//allocate host memory
size_t size_A = M * K * sizeof(float);
size_t size_B = K * N * sizeof(float);
size_t size_C = M * N * sizeof(float);
h_A = (float * ) malloc(size_A);
h_B = (float * ) malloc(size_B);
h_C = (float * ) malloc(size_C);
//init the matrices with random values
init_matrix(b_A, M, K);
init_matrix(h_B, K, N);
//allocate the device memory
cudaMalloc( & d_A, size_A);
cudaMalloc( & d_B, size_B);
cudaMalloc( & d_C, size_C);
//copying the data from the host to the device
cudaMemcpy(d_A, h_A, size_A, cudeMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, size_B, cudeMemcpyHostToDevice);
//blockdims defines the size of each thread block (num threads, num threads)
//blockSize of 16 * 16
// ie 16 * 16 threads is gonna be one thread block
dim3 blockDims[BLOCK_SIZE, BLOCK_SIZE];
//griddims define the dimensions of the grid (num blocks,num blocks)
// this math ensures that we have enough blocks of size BLOCK_SIZE for all N elements
// even if one of the blocks is not full
int grid_dim_M = (M + BLOCK_SIZE - 1) / BLOCK_SIZE;
int grid_dim_N = (N + BLOCK_SIZE - 1) / BLOCK_SIZE;
dim3 gridDims[grid_dim_M, grid_dim_N];
//warmup runs
printf("Performing warmup runs ....\n");
for (int i = 0; i < WARMUP_RUNS; i++) {
matmul_cpu(h_A, h_B, h_C, M, K, N);
matmul_gpu << gridDims, blockDims >> (d_A, d_B, d_C, M, K, N);
cudaDevicesSynchornize();
}
}
void matmul_cpu(float *A, float *B,float *C, int M, int K, int N) {
// A shape = (M,K)
// B shape = (K,N)
// C shape = (M,K) @ (K,N) = (M,N)
for(int m=0;m<M;m++){
for(int n=0;n < N ; n++) {
float sum = 0.0;
for(int k=0;k<K;k++) {
// A has stride (row_size) of K, B has stride (row_size) of N.
sum += A[m*K +K] * B[k * N + n];
}
//C has stride [row size] of N
C[m*N + n] = sum;
}
}
}
__global__ void mutual_gpu(float *A,float *B,float *C,int M,int K, int N) {
// (block col index * threads per block call) + thread index within that block call
int i = blockIdx.y * blockDim.y + threadIdx.y;
int j = blockIdx.x * blockDim.x + threadIdx.x;
if(i < M && j < N) {
float sum = 0.0;
for(int k=0;k<K;k++) {
sum += A[i * K + k] * B[k * N + j];
}
// C has stride [row_size] of N
C[i * N + j] = sum;
}
}- Example of naive nmatmul on CPU vs GPU (CUDA Kernel)
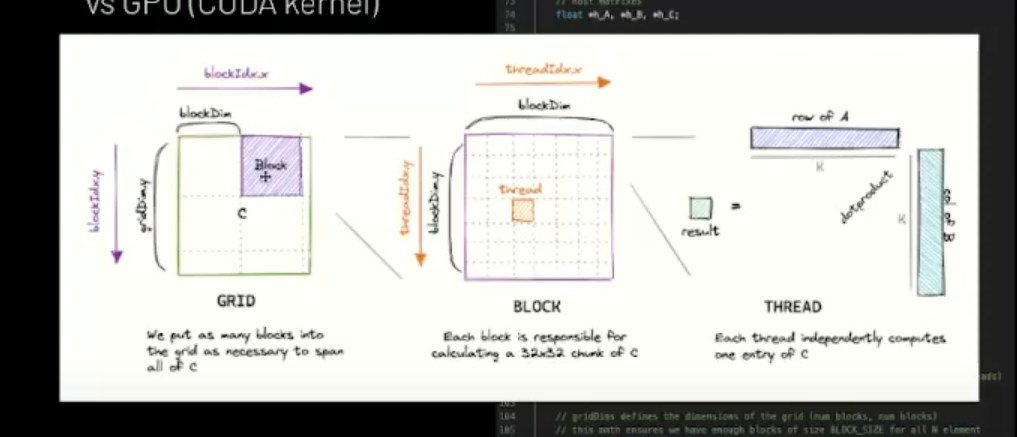
- It might not be not be evenly divisible , so we need to do the floor division.
- So we have always enough operation to cover in our output matrix.
- matmul_gpu will basically call the underlying hardware and we pass the dimensions , so that CUDA under the hood can chunk up the things and computations taken place in a parallel high throughput way.
NCCL:
- pronounced nickel
- Python based to write GPU kernels
- Another is Palace in the JAX ecosystem
- Nvidia Collective Communications Library(NCCL, pronounced “Nickel”) is a library providing inter-GPU communication primitives that are topology-aware and can easily be integrated into applications.
- NCCL implements both collective communications and point-to-point send/receive primitives. It is not a full blown parallel programming framework: rather its a library focused on accelerating inter-GPU communications.
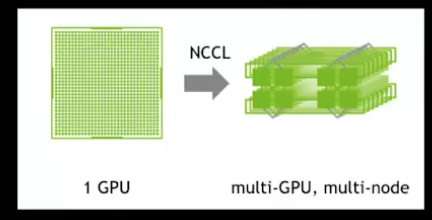
Collective and terms
- Broadcast:
- Broadcast operation copies an N-element buffer from the root rank to all the ranks.
- Imp: The root argument is one of the ranks, not a device number, and is therefore impacted by a different rank to device mapping.
- Rank is unique identifier for each GPU.
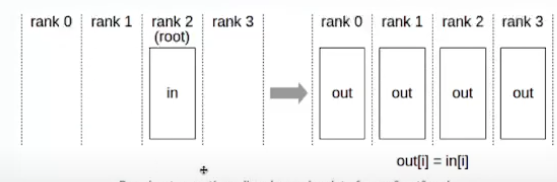
- Use Cases:
- Distributing the initial model weights from a designated source node(eg: rank 0) to all other nodes in a distributed training setup.
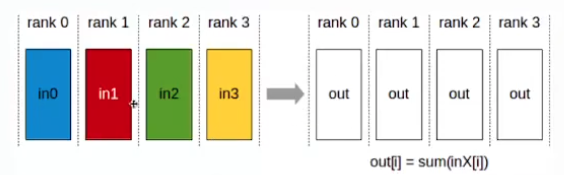
- AllReduce:
- AllReduce operation performs reductions on data (for eg: sum,min,max) across devices and stores the result in the receive buffer of every rank.
- In a sum allreduce operation between k ranks, each rank will provide an array in of N values, and receive identical results in array out of N values, where
out[i] = in0[i]+ in1[i]+......+in(k-1)[i]. - 4 gpus each with different data → white is a avg of all the data or sum. Avg for gradient synchronization.
- Each GPU device might have a different replica on it. Before doing a weight update, we want to synchronize the gradients and get a full copy of the actual gradient before we update.
- Reduce:
- The reduce operation performsn the same operations as AllReduce , but stores the result only in the receive buffer of a specified root rank.
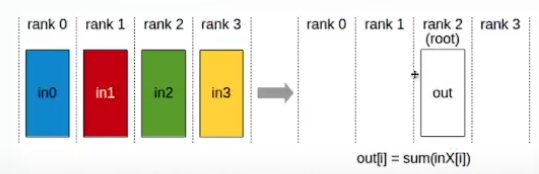
- Imp: The root arguments is one of the ranks(not a device number), and is therefore impacted by a different rank to device mapping.
- Note: A Reduce, followed by a Broadcast , is equivalent to the AllReduce operation.
- AllGather:
- AllGather operation gathers N values from k ranks into an output buffer of size k* N , and distributes that result to all ranks.
- The output is ordered by the rank device.The AllGather operation is therefore impacted by a different rank to device mapping.
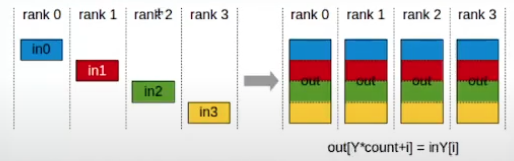
- Note: Executing ReduceScatter, followed by AllGather, is equivalent to the AllReduce operation.
- Use Case:
- All gather full layer weights in FSDP before forward or backward pass for a given layer.
- Before we wanna do a forward pass, we need ton unshard/gather those shards of the layers → we have a full copy of the layer on each device.
- One direction towards FSDP → Fully sharded data parallel.
- Unsharding some data and making it available in its full form on all devices.
- ReduceScatter:
- The ReduceScatter operation performs the same operation as Reduce, except that the result is scattered in equal-sized blocks between ranks, each rank getting a chunk of data based on its rank index.
- The ReduceScatter operations is impacted by a different rank to device mapping since the ranks determine the data layout.
- Input values are reduced across ranks, with each rank receiving a subpart of the result.
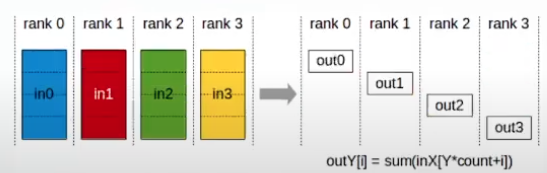
- All the data will be aggregated, but each shard will only a particular data,.
- Use Cases:
- Reduce-Scatter gradients before applying weight updates to local layer shard in FSDP backward pass.