Premise:
while i have been enjoying the original Attention is All You Need paper , i feel Illya’s edit of the Annotated Transformer model is a better outcome , both in terms of understanding for a beginner and to also understand from the ground up the basic technology used in modern chat systems.
Background of Transformer:
- Using CNN as basic building block, architectures like ByteNet, ConvS2S computes hidden representations in parallel for all input and output positions.
- In these, the number of operations required to relate signals from 2 arbitary input or output positions grows in the distance between positions.
- Linearly for ConvS2S
- Logarithmically for ByteNet
- Result: Makes it more difficult to learn dependencies between distant positions.
- Transformers reduce this to a constant number of operations , albeit at the cost of reduced effective resolution due to averaging attention-weighted positions , which is counteracted with Multi-Head Attentions.
But what exactly is attention really ?
-
Attention : a method that determines the importance of each component in a sequence relative to the other components in that sequence.
- Like in humans , attention mechanism was developed to address the weaknesses of leveraging information from the hidden layers of recurrent neural networks.
- RNN favours more recent information contained in words at the end of a sentence , while information earlier in the sentence tends to be attenuated.
- Attention allows a token equal access to any part of a sentence directly, rather than only though the previous state.
- Ref: Attention
-
Self Attention: also called as intra attention, is an attention mechanism relating different positions of a single sequence in order to compute a representation of the sequence.
- Used in a lot of tasks like → reading comprehension, abstractive summarisation, textual entailment , learning task-independent sentence representation.
Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence aligned RNNs or convolution.
Model Architecture:
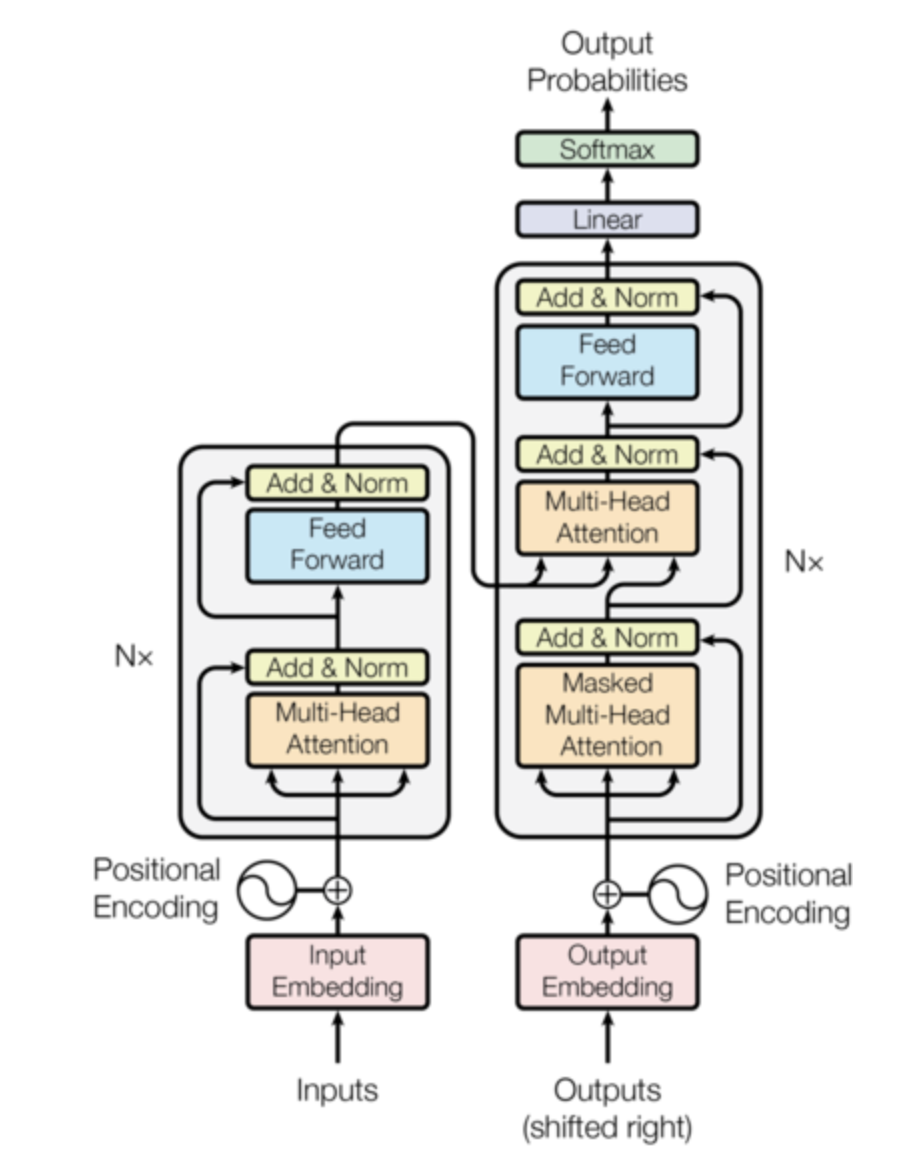
- Most competitive neural sequence transduction models have a encoder-decoder structure.
- In this:
- Encoder will map an input sequence of symbol representations to a sequence of continuous representations .
- Given ,the decoder will then generate a output sequence of symbols one element at a time.
- At each step the model is auto-regressive ie consuming the previously generated symbols as additional input when generating the next.
- Transformer will follow this overall architecture using stacked self-attention and point-wise fully connected layers for both the encoder and decoder.
Encoder:
- Encoder is composed of a stack of identical layers.
- We then employ a residual connection around each of the 2 sub-layers, followed by a layer normalization.
- i.e the output of each sub-layer is , where is the function implemented by the sub-layer itself.
- We then apply dropout to the output of each sub-layer , before it is added to the sub-layer input and normalized.
- We get an output of dimension to facilitate these residual connections , all sub-layers in the model, as well as the embedding layers.